
Neste post vou mostrar como criar um pipeline genérico de consulta de dados em uma API e armazenamento no data lake.
Utilizaremos o Data Factory (mas pode ser usando o Synapse Integrate também) para orquestrar, consumir e ingerir os dados. A ingestão será feita num Storage Account Gen 2.
Vamos consumir uma API aberta que retorna um Json de produtos cosméticos:
https://makeup-api.herokuapp.com/
Como a proposta é fazer um pipeline dinâmico, vamos utilizar uma planilha de Excel com as informações sobre a API de consumo e os containers para ingestão, desta forma qualquer alteração ou inclusão de novos endpoints a serem integrados é feita apenas nesta planilha sem a necessidade de fazer alterações no projeto. Chamaremos esta planilha de “Controller”.
Conhecendo o Ambiente
Azure Data Lake

Local onde está a planilha controller
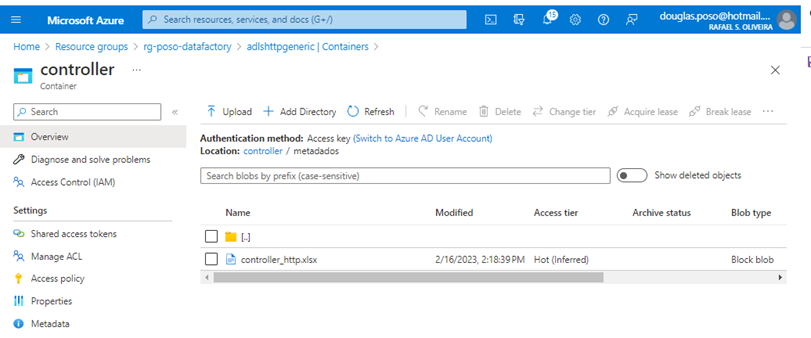
Planilha controller


É uma planilha de Excel onde criamos um layout padrão de campos. Nela incluímos as informações pertinentes ao sistema de origem (API) e de destino (Data Lake). Dados sensíveis, como senhas e chaves são armazenados em secrets do Key Vault.
Segue um descritivo dos campos que serão utilizados no processo:
source_api_url - URL da API
source_endpoint_name – Endpoint que sera consultado
source_header – Headers utilizados
container_target – Nome do container de destino no data lake
directory_target – Nome do diretório de destino
file_target – Nome do arquivo que vai ser gerado
flag_controller – flag que indica se o registro está ativo
Esta planilha será consumida no Data Factory e estes valores serão usados como parâmetros de entrada para o consumo da API e a ingestão no Data lake.
Data Factory

Configuração do projeto
Abaixo segue as configurações necessárias para criação do projeto.
Linked Sevices

Utilizaremos dois linked services:
HTTP
Data Lake
HTTP
Aqui vamos configurar a conexão com a API, porém faremos isso de forma dinâmica utilizando parâmetros, pois as informações sobre o consumo da API estão na planilha controller.
Acesse o menu lateral Manage>Linked services e clique em “New”:

Na caixa de busca digite “HTTP” e clique no botão “continue”.

A tela de configuração será aberta:

Configuraremos aqui os dados de acesso a API. Deixaremos a configuração o mais dinâmica possível, pois os dados virão da planilha controller. Segue abaixo um passo-a-passo:
1. Name- Nome do linked service, lembre-se de sempre usar um name convention.
2. Connect via integration runtime - Deixamos o Integration runtime padrão do Azure.
3. Base URL - Criamos um parâmetro (será mostrado como criar no item 6 desta lista) chamado “url” e inserimos neste campo. A Url a ser usada virá da planilha controller.
4. Authentication type - A API que estamos consumindo não possui nenhum tipo de autenticação, mas caso esteja utilizando uma que necessite, basta clicar no combo box e escolher entre as opções disponíveis:

Ao escolher uma das opções da lista os campos pertinentes a autenticação aparecerão logo abaixo.

Para nosso exemplo escolheremos a opção “Anonymous”.
5. Auth Headers - Caso sua API de consumo necessite de um header de autenticação basta clicar em “New” e escolher uma das opções:

6. Parameters - Os parâmetros que utilizamos na configuração do linked service são criados nesta seção.

Data Lake
Vamos criar mais um linked service, agora para conexão com o Data Lake. Utilizaremos as configurações padrões. No meu caso a configuração ficou da seguinte forma.

Datasets
Precisaremos de 3 Datasets neste projeto:
Dataset Datalake Excel
Será utilizado para fazer a leitura do arquivo controller. Utilizaremos o linked service de data lake e o formato de dados será excel.

** Criamos parâmetros para os campos Container, Directory, File Name e Sheet name. Quando formos utilizar este dataset passaremos os valores para estes parâmetros.
Dataset Data Lake parquet
Será utilizado para fazer a ingestão dos dados lidos da API no data lake em formato parquet. Utilizaremos o linked service de data lake e o formato de dados será parquet.

**Note que criamos parâmetros para os campos referentes a container, diretório e nome do arquivo. Estas informações virão na planilha controller.
Dataset HTTP JSON
Será utilizado para fazer a leitura do JSON retornado pela API. Utilizaremos o linked service de HTTP e formato de dados será JSON.
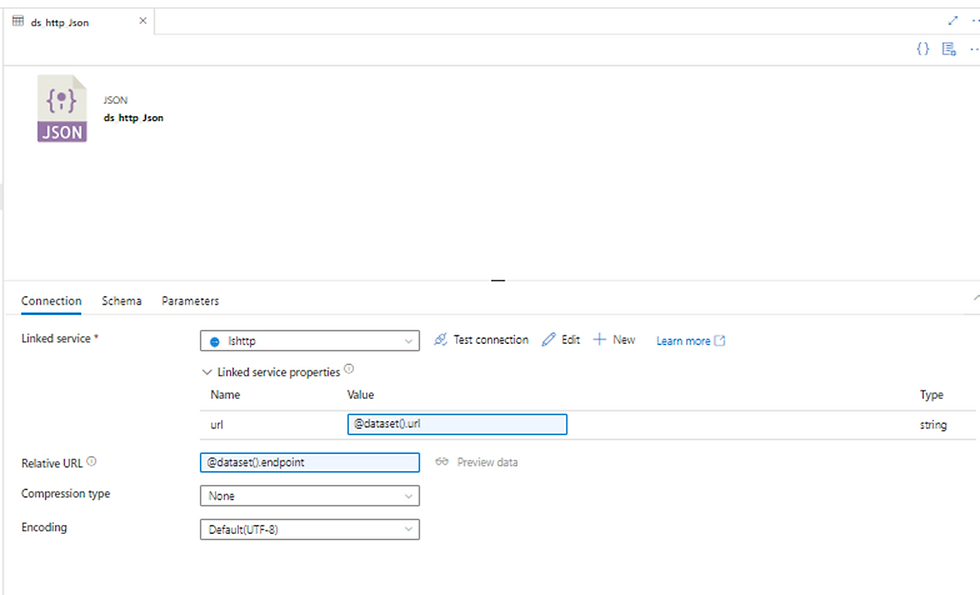
Criamos aqui dois parâmetros (aba Parameters) url e endpoint. Estes parâmetros são apontados nos seguintes campos do dataset:
url – É a URL de acesso a API. Este valor será transmitido ao pipeline pelo arquivo controller.
Relative URL – É o endpoint da API que também será transmitido ao pipeline pelo arquivo controller.
Desenvolvimento do Pipeline
O Pipeline criado tem apenas quatro activities:
Lookup
Responsável por fazer a leitura da planilha controller e a passagem dos valores para as próximas activities.

Configuração
Escolher o Dataset de excel e preencher os parâmetros manualmente. Estes parâmetros recebem o local onde a planilha controle está armazenada além de qual a aba do arquivo ele vai utilizar.

Filter

Esta activitie filtra apenas registros prontos para serem integrados o que neste caso são os registros cujo campo “flag_ativo” tem o valor 1
Configuração
No campo “Items” escolhemos a saída da activite anterior utilizando a seguinte expressão “@activity('Ler Planilha Controller').output.value”
No campo “Condition” Montamos uma expressão lógica que retorna verdadeiro quando o valor do campo “flag_controller” for igual a 1 (@equals(item().flag_controller,'1')
)

ForEach

Para cada linha existente na planilha controller com o campo flag_ativo = 1 faz a chamada da activitie de cópia passando seus valores como parâmetro.
Configuração
No campo “Items” escolhemos a saída da activite anterior utilizando a seguinte expressão “@activity('Ativo').output.value”

Copy data

Efetua o consumo da API e grava o retorno dos dados no data lake em formato parquet
Configuração Source
Escolher o Dataset JSON e nas propriedades do dataset apontar os valores de url e endpoint da planilha controller.
@item().source_api_url
@item().source_endpoint_name
Em “Request method” escolher o método GET e em “Additional headers” apontar o valor dos headers que vem da planilha controller.
@{item().source_header}

Configuração Sink
Escolher o dataset de parquet e nas propriedades do dataset apontar os valores de container, directory e file name da planilha controller.
@item().container_target
@item().directory_target
@concat(item().file_target,'.parquet')

O pipeline ao final ficará desta forma:

Resultado
Agora é hora de testar!!

Sucesso!!!

Como podemos ver na imagem acima um arquivo foi criado no Data lake. Verificando agora diretamente no container transient...

O arquivo .parquet foi criado.
Podemos fazer um preview dos dados no Data lake


Podemos pensar em nosso dia-a-dia de desenvolvimento e encaixar esta dica dentro da nossa realidade. Como o processo é dinâmico poderíamos colocar mais linhas na planilha controller apontando para outros endpoints e este pipeline iria fazer a execução sem precisar de nenhuma alteração.
Muito bom conteúdo! Top demais Poso.